
Unicorns exist
Yes, that is an odd way to start a blog post about Regular Expressions (RegEx), right? But I wanted to give it some humor. You see, a few days ago I was browsing for work on UpWork and noticed a job post that immediately caught my attention. The title was almost the exact same as this blog post (I shamelessly copied it and slightly edited it because of reasons for SEO). I enthusiastically wrote my proposal to the guy -who asked, and I quote ‘To show you have read this job, please write “Unicorns exist” at the very beginning of your answer‘. And actually I started working on it before he contacted me. Both being optimistic that he’d get back to me, and because I used to love working with RegEx when I learned about them back in college so a little brushing up on them was great.
 What wasn’t great is how time flew by and the guy didn’t get back to me. I thought well it’s way past midnight in France. Maybe in the morning. I had the work already done, after frantically going at it for around half an hour and I was eager to show it to him. In the morning I noticed the job went to someone else and that was a bit of a letdown. After some consideration I came to the conclusion that, well not everything’s lost. Since I like sharing knowledge (and my wife and my best friend didn’t understand me at all), and not to waste that time I invested in getting it done (and optimized), I can make a blog post about them and work on my 2019 goals. So without further ado, let’s talk about regular expressions! 🙂
What wasn’t great is how time flew by and the guy didn’t get back to me. I thought well it’s way past midnight in France. Maybe in the morning. I had the work already done, after frantically going at it for around half an hour and I was eager to show it to him. In the morning I noticed the job went to someone else and that was a bit of a letdown. After some consideration I came to the conclusion that, well not everything’s lost. Since I like sharing knowledge (and my wife and my best friend didn’t understand me at all), and not to waste that time I invested in getting it done (and optimized), I can make a blog post about them and work on my 2019 goals. So without further ado, let’s talk about regular expressions! 🙂
What are Regular Expressions?
Being really really brief, regular expressions (or RegEx) are basically patterns. You write up a sequence of commands that will be able to search for a defined pattern on a string and voilà. Magic.
Since I’m the worst for remembering theory and exact definitions I double checked on google, not bad.
Regular expressions are used for search engines, syntax validations, highlighting, searching and replacing text, data scraping, etc. Since I’m more of a practice guy, I want to show you how to use them with a small real life use.
Example of use
Circling back to the beginning, I’ll demonstrate the use of Regular Expressions with the case scenario I have from the UpWork job. We’ll use the following sample and we’ll evaluate it with regex101.
Phone numbers listing
TESTS
Téléphone : 01-23-45-67-89, de 8h à 8h02
Téléphone : 0123456789, de 8h à 8h02
Téléphone : 01.23.45.67.89, de 8h à 8h02
Téléphone : 01 23 45 67 89, de 8h à 8h02
Téléphone : 01-23-45-67-89, de 8h à 8h02
Téléphone : 0 123 456 789, de 8h à 8h02
Téléphone : 0.123.456.789, de 8h à 8h02
Téléphone : 0-123-456-789, de 8h à 8h02
Téléphone : 00-33-1-23-45-67-89, de 8h à 8h02
Téléphone : 00331-23-45-67-89, de 8h à 8h02
Téléphone : 0033123456789, de 8h à 8h02
Téléphone : 0033123456789, de 8h à 8h02
Téléphone : 00331.23.45.67.89, de 8h à 8h02
Téléphone : 00331 23 45 67 89, de 8h à 8h02
Téléphone : 00.33.1.23.45.67.89, de 8h à 8h02
Téléphone : 00 33 1 23 45 67 89, de 8h à 8h02
Téléphone : +33-1-23-45-67-89, de 8h à 8h02
Téléphone : +33123456789, de 8h à 8h02
Téléphone : +33.1.23.45.67.89, de 8h à 8h02
Téléphone : +33 1 23 45 67 89, de 8h à 8h02
Téléphone : (33)1-23-45-67-89, de 8h à 8h02
Téléphone : (33)123456789, de 8h à 8h02
Téléphone : (33)1.23.45.67.89, de 8h à 8h02
Téléphone : (33)1 23 45 67 89, de 8h à 8h02
Téléphone : (33)-01-23-45-67-89, de 8h à 8h02
Téléphone : (33)0123456789, de 8h à 8h02
Téléphone : (33).01.23.45.67.89, de 8h à 8h02
Téléphone : (33) 01 23 45 67 89, de 8h à 8h02
Téléphone : (0033)1-23-45-67-89, de 8h à 8h02
Téléphone : (0033)123456789, de 8h à 8h02
Téléphone : (0033)1.23.45.67.89, de 8h à 8h02
Téléphone : (0033)1 23 45 67 89, de 8h à 8h02
Téléphone : (0033)-01-23-45-67-89, de 8h à 8h02
Téléphone : (0033)0123456789, de 8h à 8h02
Téléphone : (0033).01.23.45.67.89, de 8h à 8h02
Téléphone : (0033) 01 23 45 67 89, de 8h à 8h02
Téléphone : (00 33)1-23-45-67-89, de 8h à 8h02
Téléphone : (00 33)123456789, de 8h à 8h02
Téléphone : (00 33)1.23.45.67.89, de 8h à 8h02
Téléphone : (00 33)1 23 45 67 89, de 8h à 8h02
Téléphone : (00 33)-01-23-45-67-89, de 8h à 8h02
Téléphone : (00 33)0123456789, de 8h à 8h02
Téléphone : (00 33).01.23.45.67.89, de 8h à 8h02
Téléphone : (00 33) 01 23 45 67 89, de 8h à 8h02
Téléphone : (0)1-23-45-67-89, de 8h à 8h02
Téléphone : (0)123456789, de 8h à 8h02
Téléphone : (0)1.23.45.67.89, de 8h à 8h02
Téléphone : (0)1 23 45 67 89, de 8h à 8h02
Téléphone : (+33)-01-23-45-67-89, de 8h à 8h02
Téléphone : (+33)0123456789, de 8h à 8h02
Téléphone : (+33).01.23.45.67.89, de 8h à 8h02
Téléphone : (+33) 01 23 45 67 89, de 8h à 8h02
Téléphone : (+ 33)1-23-45-67-89, de 8h à 8h02
Téléphone : (+ 33)123456789, de 8h à 8h02
Téléphone : (+ 33)1.23.45.67.89, de 8h à 8h02
Téléphone : (+ 33)1 23 45 67 89, de 8h à 8h02
Téléphone : (+ 33)-01-23-45-67-89, de 8h à 8h02
Téléphone : (+ 33)0123456789, de 8h à 8h02
Téléphone : (+ 33).01.23.45.67.89, de 8h à 8h02
Téléphone : (+ 33) 01 23 45 67 89, de 8h à 8h02
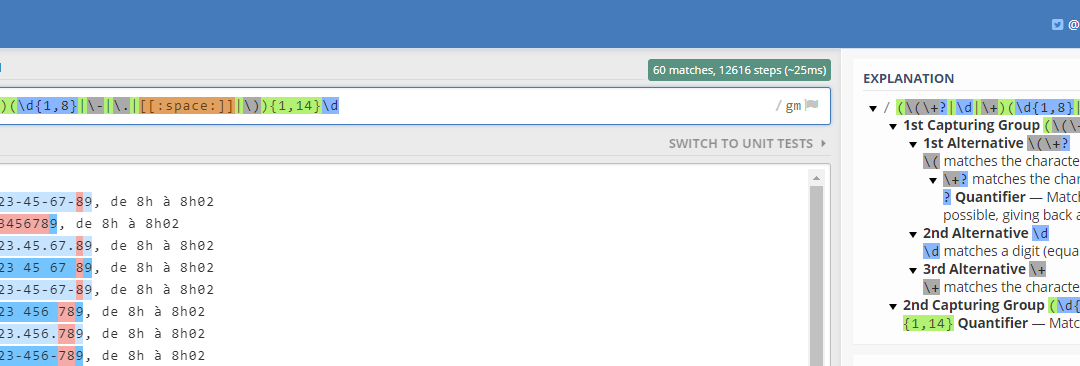
The goal here is to identify all the phone numbers, disregarding the variety of formats, national or international, parenthesis, distinct separators, etc. And nothing else but the phone numbers, we’ll need to ignore the rest of the content, not a single additional character or space can come through. I know before hand by examining the list that there are 60 valid phone numbers there, in a wide variety of formats and presentations.
Spoiler alert: the answer to this one is at the end of the post. You could take a look at it and try to read it and understand it if you feel adventurous! Either way, I invite you to keep reading, I’ll get there step by step.
Important note: from this point forward I encourage you to read it on a computer so you’re able to see the screenshots better and to follow along with the exercise with me.
Numbers and quantifiers
First thing that comes to mind as a starting point is the “\d” syntax which brings us a single numeric character. Now if you want more than one, you could add a quantifier, like this:
-
\d{n}Equals to a numeric character of “n” length of digits.
-
\d{min,max}Equals to a number ranging from said min / max amount of digits.
-
\d{min,}Equals to a number with that minimum amount of digits, and not max limit.
-
\d?
Equals to zero or one number.
-
\d*
Equals to zero or more numbers (no max limit).
-
\d+
Equals to at least one number.
(please note that quantification can be used for pretty much anything in regular expressions, not just numbers)
Let’s run an example on regex101 and see what brings us, shall we?
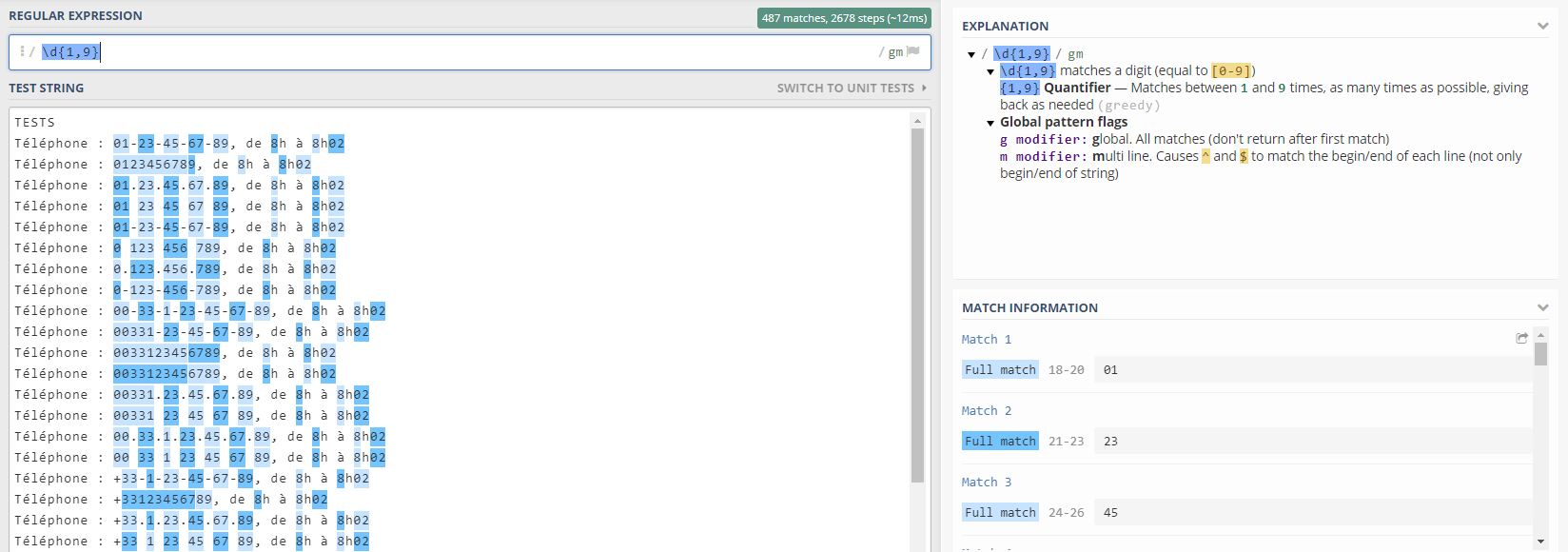
Say for instance, using “\d{1,9}” yields 487 results. There are 487 matches in that list that could be defined as numbers ranging from 1 to 9 digits. This is far off the 60 phone numbers, since it’s splitting them because it doesn’t take in consideration the special characters or formatting, and it even reads the extra numbers at the end of each string. I invite you to play a bit with it, try different approaches using what you’ve learned so far and see what you can come up with at this stage. Fun, right?*
Special characters
Now let’s focus for a second here on those special characters and separators. There are six of them: “+“, “(“, “)“, “.“, “–” and the empty space. To avoid using those characters as syntax (as a part of our regular expressions), we need to escape them by adding a backslash before them, meaning they’d be written like this “\+“, “\(“, “\)“, “\.“, “\-“, except with the space, which you can write as “[[:space:]]”. I invite you again to explore a bit, try searching each one of them and see the results yourself.
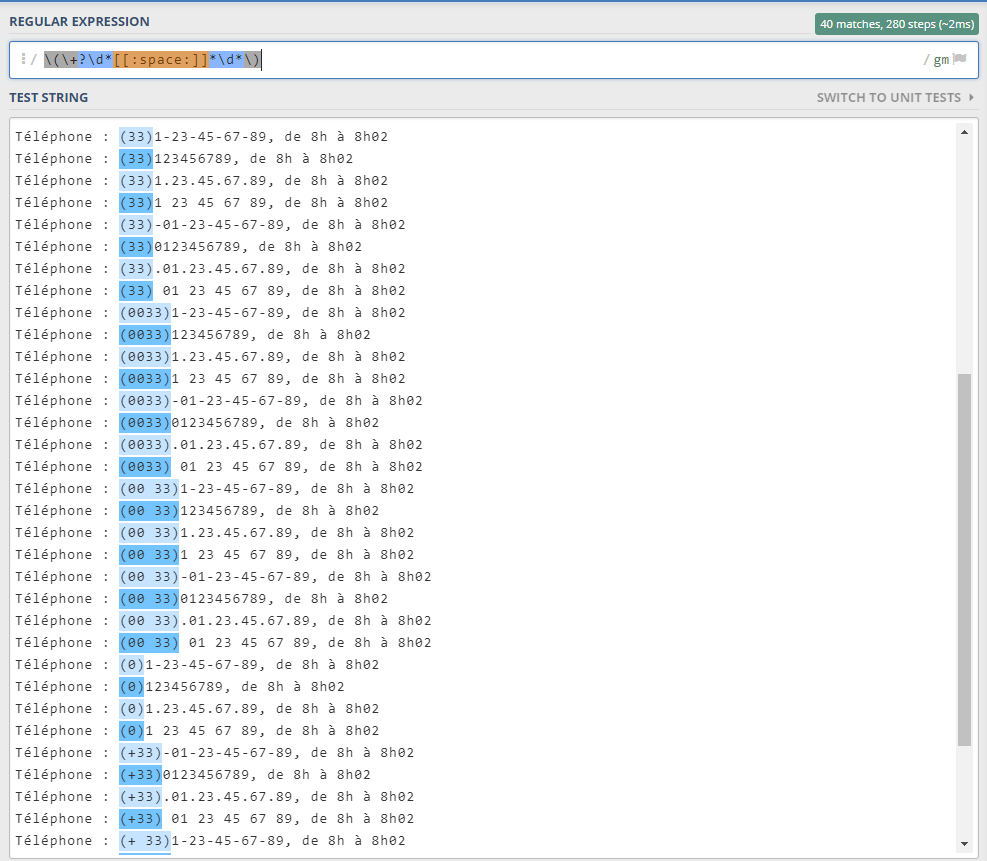
Knowing what we know so far, we could try something interesting. Let’s make a pattern for identifying the parenthesis that some phone numbers have at the beginning. We know of course that there’s an opening parenthesis, so “\(” is our obvious start point. Some numbers do have a single “+” right after the opening parenthesis, that’s zero or one, does that ring any bell?. Then we have some numbers, which may or may not be separated by some space, and finally closing parenthesis. Something along these lines:
\(\d*\+?[[:space:]]*\d*\)
Grouping and alternatives
Let’s mix things a bit more. Using the vertical bar “|” we have an “or” statement. For instance “a|b” we can get either “a” or “b”. Pretty basic, right? In that same way with “LIVE|LOVE” RegEx, both LIVE and LOVE fit that pattern, but obviously there’s not much of a point on doing it like that. We can group elements with parenthesis “()” to apply operations only on a specific part of our pattern. Back to our mini-example, “L(I|O)VE” is a much more effective pattern.
Applying that knowledge to our current phone numbers example, let’s try to get the first four phone numbers on the list, given that they are four different formats, they’ll fit well to test this.
- First format is split in groups of two numbers divided by dashes. This would do:
-
\d{2}\-\d{2}\-\d{2}\-\d{2}\-\d{2}
-
- Second format is a 10 digit number. Easy:
-
\d{10}
-
- Third format is split in groups of two numbers divided by dots. Pretty much the same as the first one, but with a different separator:
-
\d{2}\.\d{2}\.\d{2}\.\d{2}\.\d{2}
-
- And finally, the fourth format is split in groups of two numbers divided by spaces. You guessed it, same logic as the first or third one:
-
\d{2}[[:space:]]\d{2}[[:space:]]\d{2}[[:space:]]\d{2}[[:space:]]\d{2}
-
With that in mind, we can group them together, each one inside parenthesis, and alternate them with the vertical bar; ending up with a monstrosity like this. Which while it works, it’s not quite efficient (please, make sure to try it as well):
(\d{2}\-\d{2}\-\d{2}\-\d{2}\-\d{2})|\d{10}|(\d{2}\.\d{2}\.\d{2}\.\d{2}\.\d{2})|(\d{2}[[:space:]]\d{2}[[:space:]]\d{2}[[:space:]]\d{2}[[:space:]]\d{2})
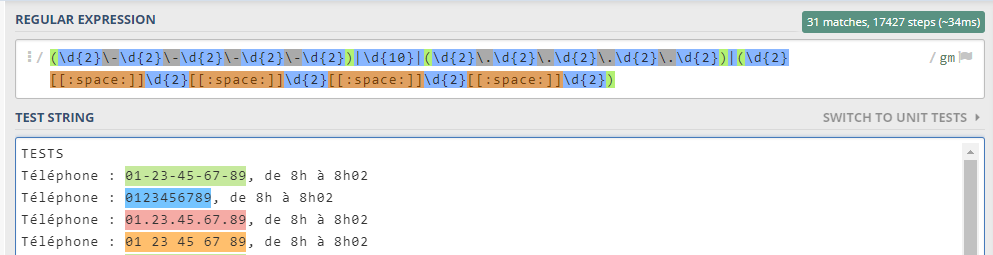
Optimizing our Regular Expressions
Let’s keep our focus on those four patterns for now. We can simplify those formats as a couple of numbers and a separator. By simply taking a look at the numbers or our current regular expressions we can tell they’re repetitive, we start noticing the patterns, and we can work our way into making shorter and more efficient regular expressions.
Remember what I told you before about quantification being applicable to anything, not just numbers? Let’s dive into that. If we have a repetitive pattern, we can express it just once and define how many times it repeats itself, by the use of quantifiers. Just englobe everything you want to repeat in parenthesis and add a quantifier (any of the six works).
For example, three of our four formats are two numbers and a separator, that of which repeats itself four times, and it ends again with two more numbers. The other is a simple 10-digit number. Even by reading it like this sounds quite easy, right? Let’s translate these simple lines into a proper regular expression.
(Two numbers “\d{2}” and a separator “(\-|\.|[[:space:]])“, that of which repeats itself four times)”{4}“, and it ends again with two more numbers “\d{2}” | The other is a simple 10 digit number “\d{10}“.
Just the RegEx now:
(\d{2}(\-|\.|[[:space:]])){4}\d{2}|\d{10}
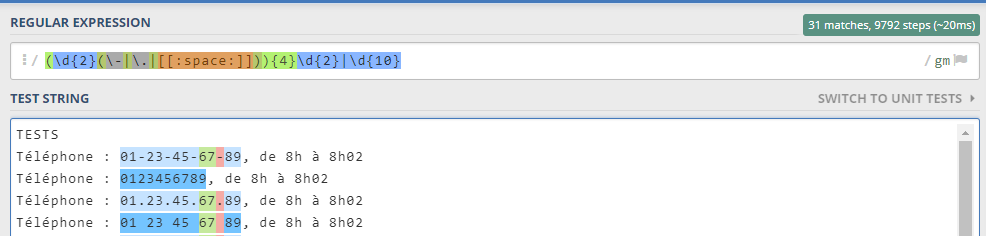
If you’ve been paying attention, on the right upper corner there’s some details on number of matches, amount of steps it took to get there and time of execution. You may notice this one is way more efficient than the previous one, achieving the same results in around half the time and steps.
Wrapping up
With everything we’ve learned so far on regular expressions, and some careful inspection of the sample, we can actually come up with a single line solution for this. And even then, we can take some time to improve it furthermore, making up for an optimal and quicker run. I myself came up with three iterations each one better than the last. While I was waiting for the guy to appear on UpWork I kept working on it and made it better and better. I’ll share all three for you to review and consider. No explanation though. I trust anyone would be able to understand them by now after this brief lesson! 🙂
V1 (16581 steps):
((\(\d*\+?[[:space:]]*\d*\)|\+)(\.|\-|[[:space:]])?)?(\d{1,9}(\.|\-|[[:space:]])?){1,6}\d{2,3}
V2 (15910 steps):
(\d{1,2}|\(|\+){1,2}(\d{1,15}|\-|\.|[[:space:]]|\)){1,13}\d{2}
V3 and final… for now (12271 steps):
(\(\+?|\d|\+)(\d{1,8}|\-|\.|[[:space:]]|\)){1,12}\d{1,2}

*=my definition of fun may vary from yours. ‘n.n
I’m eager to hear from you. What do you think? Did you enjoy this post and learn from it? Did you try the examples and experimented on your own with the Regular Expressions along the way? 🙂 Do you understand the final versions for the entire sample? And most important, can you do it better? I’ll be delighted if you do.
Recent Comments